字段权限控制
原理: 字段权限是通过 djangorestframework 中的 ModelSerializer 来实现。
若要使用字段权限,则需要继承 BaseModelSerializer 参考 system/utils/serializer.py
- 请求先通过
common.core.permission.IsAuthenticated, 获取该请求的菜单,通过菜单获取绑定的模型,通过模型获取字段 - 然后在使用
common.core.serializers.BaseModelSerializer的时候,会调用__init__方法,在该方法中定义了所需字段
如何使用?本次使用是查询用户权限
1. 在前端页面菜单中,添加权限,然后选择关联模型
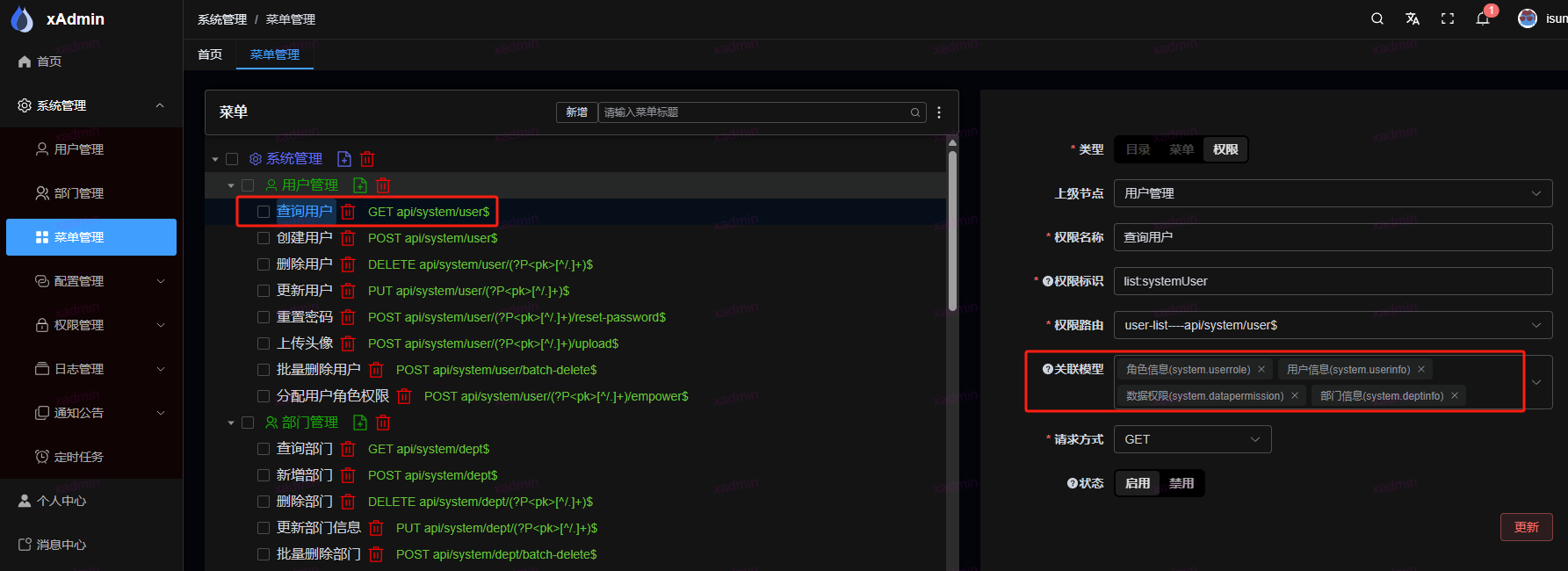
为什么要关联这四个模型?
代码中system/serializers/base.py部分代码如下
python
class BaseRoleRuleInfo(BaseModelSerializer):
roles = BasePrimaryKeyRelatedField(queryset=UserRole.objects, allow_null=True, required=False, format="{name}",
attrs=['pk', 'name', 'code'], label=_("Role permission"), many=True)
rules = BasePrimaryKeyRelatedField(queryset=DataPermission.objects, allow_null=True, required=False, many=True,
format="{name}", attrs=['pk', 'name', 'get_mode_type_display'],
label=_("Data permission"))
mode_type = LabeledChoiceField(choices=ModeTypeAbstract.ModeChoices.choices, label=_("Mode type"),
default=ModeTypeAbstract.ModeChoices.OR.value)
class UserSerializer(BaseRoleRuleInfo):
class Meta:
model = UserInfo
fields = ['pk', 'avatar', 'username', 'nickname', 'phone', 'email', 'gender', 'block', 'is_active',
'password', 'dept', 'description', 'last_login', 'date_joined', 'roles', 'rules', 'mode_type']
extra_kwargs = {'last_login': {'read_only': True}, 'date_joined': {'read_only': True},
'rules': {'read_only': True}, 'pk': {'read_only': True}, 'avatar': {'read_only': True},
'roles': {'read_only': True}, 'dept': {'required': True}, 'password': {'write_only': True},
'email': {'validators': [UniqueValidator(queryset=UserInfo.objects.all())]},
'phone': {'validators': [UniqueValidator(queryset=UserInfo.objects.all())]},
}
read_only_fields = ['pk'] + list(set([x.name for x in UserInfo._meta.fields]) - set(fields))
table_fields = ['pk', 'avatar', 'username', 'nickname', 'gender', 'block', 'is_active', 'dept', 'phone',
'last_login', 'date_joined', 'roles', 'rules']
dept = BasePrimaryKeyRelatedField(queryset=DeptInfo.objects, allow_null=True, required=False,
attrs=['pk', 'name', 'parent_id'], label=_("Department"), format="{name}")
gender = LabeledChoiceField(choices=UserInfo.GenderChoices.choices,
default=UserInfo.GenderChoices.UNKNOWN, label=_("Gender"))
block = input_wrapper(serializers.SerializerMethodField)(read_only=True, input_type='boolean',
label=_("Login blocked"))获取用户的序列化方法,里面使用了roles 角色模型,dept 部门模型,rules 数据权限模型 ,还有自己本身的UserInfo 模型
2. 在 角色权限中,创建角色,并关联字段
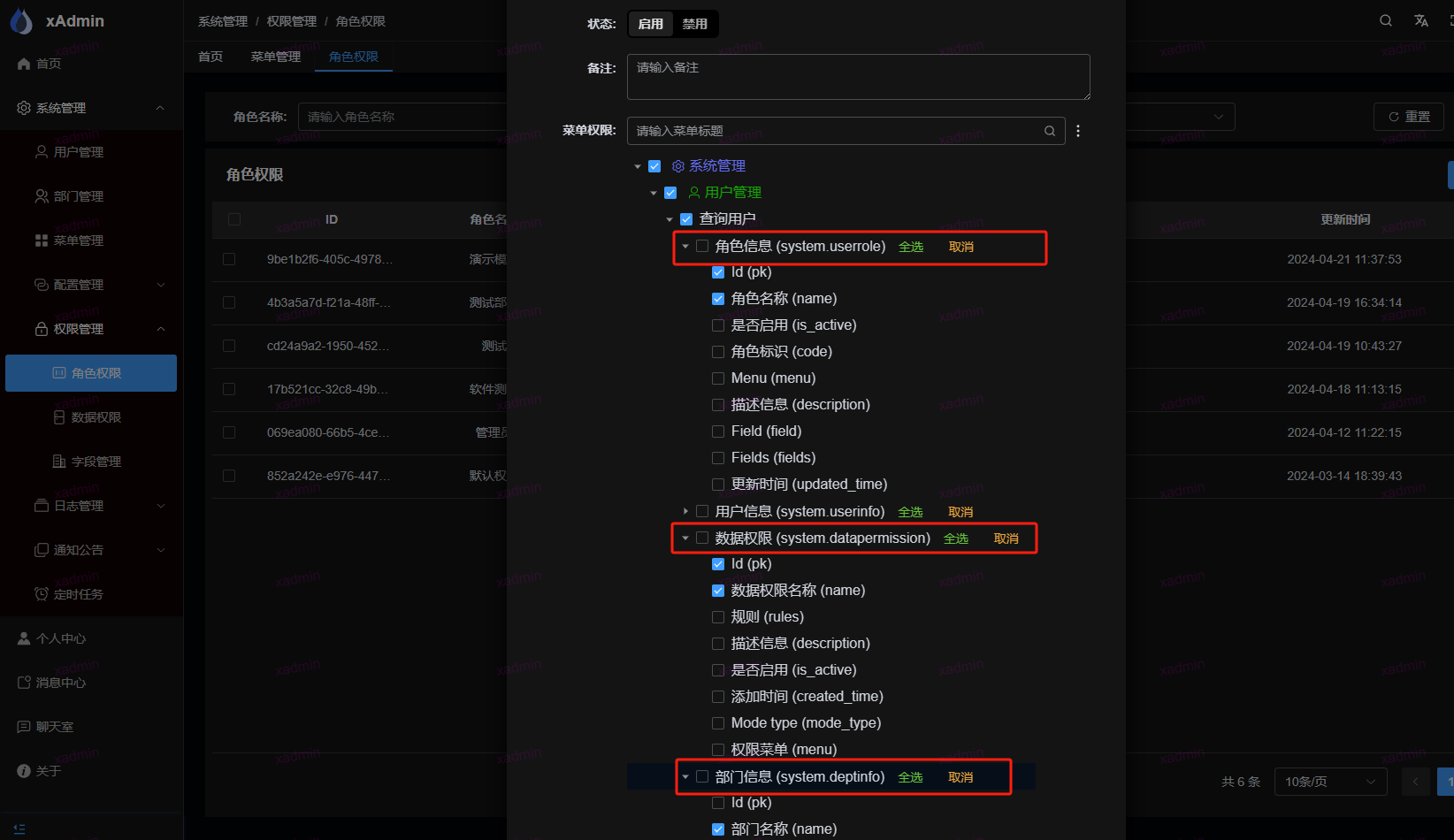
为什么查询用户下面有四个?
之前关联的模型有几个,查询用户下面就会有几个字段选择模型
为什么角色信息,数据权限中,进勾选了 Id (pk),角色名称|数据权限名称 (name)
python
roles = BasePrimaryKeyRelatedField(queryset=UserRole.objects, allow_null=True, required=False, format="{name}",
attrs=['pk', 'name', 'code'], label=_("Role permission"), many=True)
rules = BasePrimaryKeyRelatedField(queryset=DataPermission.objects, allow_null=True, required=False, many=True,
format="{name}", attrs=['pk', 'name', 'get_mode_type_display'],
label=_("Data permission"))这两个,因为上面定义的用户序列化方法中,仅仅使用了这两个字段, 其他字段无需勾选,勾选也不会显示,如果要想显示其他字段,则需在修改如下
python
roles = RoleSerializer(ignore_field_permission=True, many=True, read_only=True, source='roles')